Измерения в социальных медиа зависят как об объема, так и качества данных
Чем больше развиваются социальные платформы, тем больше данных генерируют увлеченные пользователи. Информация из социальных сетей становится горячим товаром в сфере маркетинговых исследований

Но могут ли измерения, основанные на данных мониторинга соцсетей, быть сопоставимы с другими, более традиционными формами исследования? Действительно ли бренд-менеджер может получить достоверные сведения о ценности бренда, основываясь на результатах подобных изысканий?
Мы считаем, что пока еще рано говорить об этом с полной уверенностью, несмотря на то, что такая информация уже эффективно использовалась пиар-специалистами и маркетологами в течение последних лет. Использование мониторинговых методов для кризис-менеджмента и управления рекламными кампаниями позволяет с помощью широкого набора измеряемых параметров в режиме реального времени тщательно выверять каждый следующий шаг. Для этих целей достаточно данных качественных исследований, их уточнение с помощью количественных методов не требуется.
Однако заинтересованность аналитиков и бренд-стратегов в использовании получаемых из соцсетей данных растет. Они хотели бы поставить их в один ряд с другими традиционно используемыми показателями, например, поведенческими. В этом смысле результаты мониторинга социальных медиа необходимо рассматривать так же тщательно, как и результаты традиционных измерений.
Emerging Media Lab (входит в Millward Brown) изучила более 60 брендов и более 30 миллионов высказываний людей в онлайн-дискуссиях, чтобы выделить наиболее подходящие методы работы с измерениями в социальных сетях с точки зрения перспектив для брендов. Наше заключение? Будущее исследований в социальных медиа напрямую зависит от стандартов качества данных.
Чем отличается «голос социальных медиа»?
Данные мониторинга социальных сетей принципиально отличаются от результатов традиционных измерений. Может сложиться впечатление, что люди говорят двумя разными голосами. Как демонстрирует Рисунок 1, «опросный» голос потребителей» звучит под влиянием структурированных и воспроизводимых условий, в то время как «голос социальных медиа» наблюдается в нестабильной внешней среде.
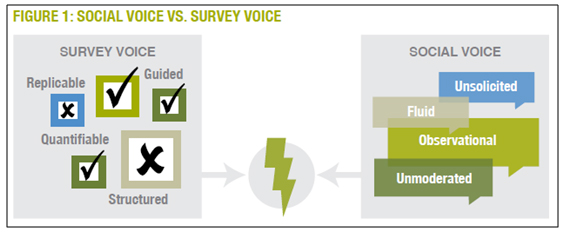
Рисунок 1. «Опросный» голос опроса» VS «Голос социальной сети»
Источник: Anne Czernek. Social measurement depends on data quantity and
quality
Трудность, прежде всего, заключается в том, чтобы сделать эти два массива данных пригодными для сравнения, а затем установить связи между ними. Методологические проблемы возникают из-за сущности доступных нам примеров каждого из двух массивов.
Традиционно измерения здоровья марки (brand tracking) и ценности бренда (brand equity) основаны на наблюдении за статистически идентичными группами людей через определенные промежутки времени. Весомость мнения отдельных индивидов в подобных количественных исследованиях может быть различной, лишь бы в результате обеспечивалось требование репрезентативности.
Но в социальной сети мы наблюдаем объекты, которые постоянно меняются, они подвижны, причем, требование репрезентативности в ним не применимо. Активные участники той или иной дискуссии могут переусердствовать, акцентируя внимание на волнующей их теме. Одновременно люди, имеющие позитивный, но не слишком большой опыт общения с брендом, могут просто не видеть необходимости как-то выразить свое мнение. И они молчат. Невозможно эффективно оценить такие реакции, так как необходимая для классификации респондентов информация просто отсутствует. Таким образом, очень трудно, если не сказать невозможно, определить, представляет ли человек, опубликовавший пост, твит или комментарий о бренде, интересующую исследователя аудиторию, репрезентирует ли он ее.
Мы ожидаем, что использование профилей в соцсетях через некоторое время улучшит ситуацию, поскольку тогда мы сможем работать с большим числом признаков посетителей. Но даже в этом случае останутся проблемы, например, дублирование. Как мы можем быть уверены, один ли человек опубликовал что-то пять раз – в Facebook, Twitter, Tumblr, Blogger и на форуме – или же пять разных людей оставили одинаковые отзывы?
Определение границ вселенной социальных медиа
Сегодня единственная возможность решить проблему дублирования пользователей и нехватки характеристик – это обозначить границы, внутри которых мы проводим мониторинг. Нам придется ввести ограничения.
Присущее всем нам желание всегда быть на связи породило расширяющуюся экосистему технологических платформ. В результате основной методикой мониторинга социальных медиа становится сбор как можно большего объема данных из всех возможных платформ: Facebook, Twitter, Instagram, Pinterest, Tumblr и так далее. Но подходят ли для наших целей, например, комментарии к новой статье? А как быть с обзорами на таких порталах, как Yelp? Как определить границы универсума социальных медиа?
Кажется, что границы мира социальных медиа туманны, так же, как и границы настоящей Вселенной. В обоих случаях они к тому же постоянно расширяются. Без согласованного определения границ этой вселенной – или хотя бы того, что мы подразумеваем под термином «социальные» - крайне трудно определить, действительно ли происходит сбор релевантной информации.
Конечно, есть еще значимые различия между типами данных, размещенных на разных платформах. Дискуссии в блогах и на форумах обычно более структурированы и ближе к стилю разговору, нежели посты в Facebook и Twitter , которые создаются и публикуются «на ходу». Кроме того, от платформы зависит, каким образом отдельные высказывания можно объединить в поток данных. Так, например, Twitter монетизировал свой «пожарный шланг» и берет комиссию за полный доступ к нему. («Эффект пожарного шланга» - ситуация в сети, когда источник передачи данных (компьютер или терминал) посылает запросы слишком быстро, из-за чего пункт приема данных (компьютер или терминал) не успевает их обработать. Термин основан на аналогии между потоком данных и потоком воды через пожарный рукав высокого давления, используемый в борьбе с огнем. В данном случае подразумевается непрерывный поток сообщений в Twitter. – Прим. перев.)
Yelp, напротив, предоставляет возможность использовать коллекцию своих обзоров для исследований. В Таблице 1 показано, какие данные доступны исследователю на разных платформах.
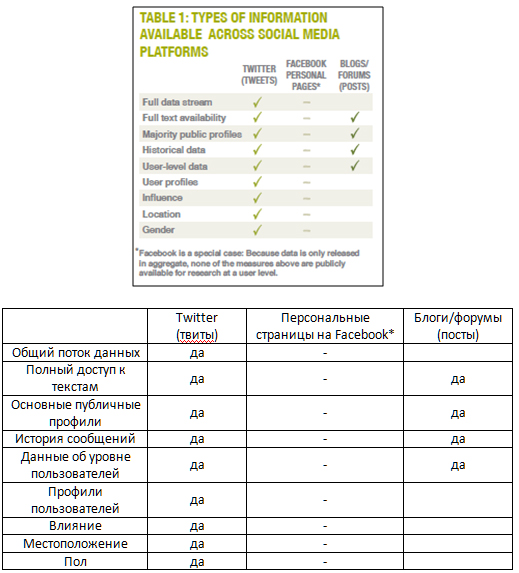
*Facebook – особый случай. В связи с тем, что данные представляются в совокупности, ни один из представленных выше маркеров не доступен для исследования на уровне пользователя.
Таблица 1. Типы информации, доступные на различных
платформах.
Источник: Anne Czernek. Social measurement depends on data quantity and
quality
Twitter – лучший ресурс для проведения исследований в социальных медиа. На сегодня.
Все выводы, сделанные нами ранее, говорят о том, что при проведении исследования в социальных сетях лучше всего опираться на данные, полученные из одного источника, и в этом смысле Twitter – лучший выход. Он открытый и гибкий, он представляет собой самую большую информационную платформу в мире. К тому же поток твитов обладает рядом полезных для исследования характеристик (полный текст сообщения, ID пользователя, отметки о времени публикации). Это позволяет выяснить больше не только о самом сообщении, но и о пользователе. В этом смысле Twitter отвечает нашим требованиям об информации на уровне респондента в заданных границах массива данных.
Более того, благодаря тому, как люди используют и воспринимают Twitter, этот ресурс представляется наиболее репрезентативным с точки зрения широты социального пространства. Исследование Dynamic Logic’s 2010 AdReaction показало, что потребители рассматривают Facebook скорее как инструмент для общения с близкими и друзьями, в то время как Twitter для них – информационная платформа для обучения, исследования и распространения знаний. (аналогичное исследование в России с учетом местных реалий было проведено в 2010 году компанией Millward Brown ARMI-Marketing – прим. перев.). Несмотря на то, что за прошедшие два года многое в сфере социальных медиа изменилось, эти наблюдения по-прежнему жизнеспособны. Facebook остается главной платформой для общения. Но потребители также используют небольшие нишевые тематические социальные сети, чтобы искать и распространять информацию о своих хобби: кулинарии, фотографии, спорте и т.п. И когда приходит время наиболее интересным сообщениям выйти за границы этих сайтов, они чаще всего попадают в Twitter, который в этом смысле представляет собой лучший ресурс-агрегатор для поиска и распространения знаний.
Трудности перевода
Однако выбором источника информации для исследования работа не ограничивается. Требуется дальнейшая переработка полученных данных мониторинга социальных сетей.
Несмотря на то, что Twitter – идеальный ресурс для проведения исследования, далеко не все данные оттуда могут быть использованы. Проверка более чем 30 млн твитов показала, что почти 60% информации, полученной из Twitter, нужно удалить из массива данных прежде, чем его анализировать. В Twitter есть две проблемы, способные снизить качество данных:
1. Многозначность ключевых слов
Сбор данных в социальных сетях производится с помощью поиска по ключевым словам. Так что если бренд назван обычным распространенным в языке словом, то большая доля найденной информации окажется «не про то». Например, при попытке мониторинга сообщений о сети быстрого питания Subway (в дословном переводе – «метрополитен» (ам.англ.) – Прим.пер.) в результатах поиска было очень много упоминаний о транспортной системе Нью-Йорка. Многозначность не только искажает смысл дискуссий, за которыми ведется наблюдение, но и наносит ущерб другим маркерам, например, проявлениям эмоций. Конечно, отмена поезда в метро, ставшая поводом для множества жалоб, не имеет ничего общего с сэндвичем за пять долларов.
2. Спам
Спам-контент все больше и больше расползается в Twitter-пространстве. Как показано на Рисунке 2, половина упоминаний брендов упакованных товаров повседневного спроса (CPG-бренды) на самом деле являлась спамом. Когда спам-комментарии удаляются, «сетевые настроения» имеют обыкновение снижаться, (показатель «сетевого настроения» рассчитывается путем сложения числа положительных и нейтральных сообщений (в процентном выражении), а затем вычитания из полученной суммы числа негативных комментариев). Это происходит из-за того, что большая часть спам-сообщений написана в нейтральном тоне, например: «оцени это предложение», и в итоге, после их удаления увеличивается доля негативных комментариев, как показано на Рисунке 3.
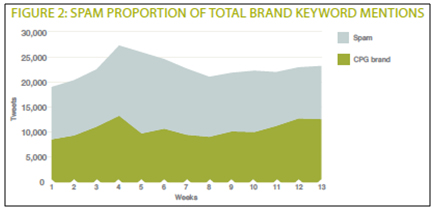
Рисунок 2. Доля спама в общем массиве упоминаний бренда
Источник: Anne Czernek. Social measurement depends on data quantity and
quality
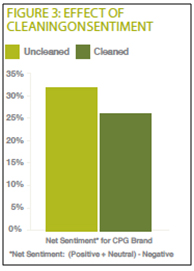
Рисунок 3. Влияние «чистки» на показатели настроения
Источник: Anne Czernek. Social measurement depends on data quantity and
quality
Будущее исследований в социальных медиа
Эффективность исследований в социальных медиа требует особого внимания к качеству используемых данных. Нынешний уровень развития технологий позволяет создать массив данных с помощью NLP (Обработка естественного языка – синтез информатики, лингвистики и возможностей искусственного интеллекта, с помощью которого изучаются вопросы компьютерного анализа и синтеза естественных языков. В итоге создается модель взаимодействия человека и компьютера – Прим.пер.) и применения правила Байеса при «очистке» (Теорема Байеса позволяет определить вероятность наступления какое-либо события, при наличии лишь косвенных, а потому могущих быть неточными, подтверждений этого – Прим.пер.) Однако участие человека в процессе по-прежнему необходимо для того, чтобы оценить источник данных, его качество и важность.
Несмотря на то, что, как мы полагаем, данные мониторинга социальных сетей позволяют оценить деятельность той или иной компании, дальнейшая работа заключается в том, чтобы понять, есть ли – если есть – прямая зависимость с ценностью бренда. Забегая вперед, можно сказать, что Millward Brown и Dynamic Logic сейчас изучают, как соотносятся с ценностью бренда результаты изучения их деятельности в социальных сетях -- то, что мы называем «социальной жизнеспособностью». Мы рассматриваем ее как наиболее важный индикатор деятельности бренда, способный также помочь оценить влияние на восприятие бренда событий и СМИ. Данное исследование сейчас в самом разгаре, и о его результатах мы сможем рассказать в ближайшие месяцы.
Первый шаг к использованию социальных медиа для маркетинговых исследований – получение массива данных, для работы с которым применимы стандартные методики, завоевавшие доверие. Мы должны быть уверены, что имеем дело с релевантными данными, собранными на платформах, обладающих и широтой, и глубиной. И мы должны заранее очистить этот массив от спама и не относящихся к теме ссылок. Только после этого можно говорить о том, что в итоге решения будут обоснованными и принятыми на основе анализа надежных данных.
Мнение российского эксперта
Павел Лебедев, Wobot, директор по исследованиям
Хорошая статья, правильная. Правда, автор пытается в новых условиях использовать лекала дизайна исследований, взятые из традиционных исследований. Но в ситуации переходного периода шероховатостей, безусловно, не избежать. Нужно будет проделать еще много экспериментов, сравнивая данные традиционных и новых методов. Нужны коэффициенты пересчета. Мы ведь живем в мире условных показателей.
Переход не будет быстрым. Нужно будет время, чтобы отрасль адаптировалась к новым индикаторам и показателям. И надо, чтобы обычные люди поняли, что их мнение является публичным со всеми вытекающими последствиями, что, кстати, грозит существенным сдвигом в общественном сознании, но это другой вопрос.
Отдельная история – возможность использования в наших условиях Твиттера в качестве базового соцмедиа. Его проникновение в России существенно меньше, чем, скажем, в США, и аналогичную функцию выполняет сеть ВКонтакте. Хотя уже сейчас количество высказываний в российском Твиттере существенно больше, чем в любой другой соцсети, это мало что дает для изучения брендов. «Высказывания» в нашем Твиттере, чаще всего, представляют собой ссылки на статьи, репосты новостных лент, и .т.п. Отзывы о брендах от реальных пользователей встречаются существенно реже. И это еще раз актуализирует вопрос об организации правильной работы с массивом данных: чистка, обработка, взвешивание относительно объема аудитории того или иного соцмедиа и т.п.
Источник: Research&Trends

