Что стоит за цифрами: возможности текстовой аналитики в спорте
Существует стереотип, что для спортивных прогнозов нужно проанализировать только цифры предыдущих результатов игроков. Но кто сказал, что это лучшее, на что способен спортсмен? Или, наоборот, откуда уверенность в том, что в будущем высокий уровень сохранится? А если потенциал игрока еще не раскрыт, что тогда? Увидеть то, что стоит за цифрами, помогает текстовая аналитика неструктурированных данных. Как именно, рассказывает Фрэнк Сильва — технический руководитель подразделения спортивной аналитики SAS

Не повод для скепсиса
Люди, которые скептически относятся к спортивной аналитике, любят подчеркивать, что она не способна показать то, что находится за пределами таблицы результатов. Игрок, который хватает мяч в падении и не дает ему выкатиться за пределы поля, обманные маневры атакующих, инструкции, которые дает товарищам по команде вратарь, — все это, по мнению критиков, можно увидеть только своими глазами непосредственно при просмотре игры.
Доля правды в этом есть. Традиционные структурированные данные, которыми в настоящее время оперируют в спорте, не позволяют учесть многие составляющие игры, так как они доступны только тренированному глазу опытного наблюдателя. Тем не менее данные собирают, сами того не замечая, подразделения, которые ищут талантливых игроков, — проще говоря, скауты. Все, что тренеры и скауты видят и замечают, они, как правило, записывают. Получаются неструктурированные данные, которые просто-напросто ждут своего часа для сбора и анализа.
Давайте прикинем, как неструктурированные массивы данных можно использовать в спорте для оценки потенциала игроков и прогнозирования их будущих результатов. Для примера мы возьмем отчеты скаутов, которые находятся в открытом доступе, — данные NBA за 2009–2015 гг. Все эти отчеты были написаны перед отбором игроков, что делает их идеальным материалом для построения предиктивной модели. Итак, зададимся вопросом: можно ли на основе одних лишь текстовых данных строить достоверные прогнозы, насколько хорошо может себя показать себя в будущем тот или иной игрок NBA?
От неструктурированных данных к структурированным
Чтобы неструктурированные данные можно было проанализировать, сначала их необходимо перевести в структурированный формат с помощью моделей текстовой аналитики. После этого на основе ее результатов можно приступать к построению прогнозных моделей. Существуют разные пути использования моделей текстовой аналитики для превращения неструктурированных наборов данных, например отчетов скаутов, в традиционный структурированный массив данных с табличными строками и столбцами. В нашей работе мы использовали два метода: категоризация на основе правил и создание тем на основе алгоритмов.
Для первого метода требуются написанные человеком логические правила, чтобы категоризировать весь скаутский отчет. Проще говоря, за каждую категорию сильных и слабых сторон, упоминаемых в отчете, присваиваются баллы. Например, возьмем такой пассаж из записи:
Майкл Кид-Гилкрист — игрок с отличными физическими данными, который пытается наносить удары с неверной позиции.
В этой фразе мы видим попадание сразу в две категории. Майкл Кид-Гилкрист, во-первых, вписывается в категорию «хорошие физические данные», во-вторых, в категорию «плохой снайпер». В нашем анализе на основе открытых скаутских отчетов NBA было выделено 17 таких категорий.
Второй метод использует возможности SAS для обработки естественного языка. Работает это так: алгоритм ищет частотные варианты сочетаний одних и тех же слов, а потом сканирует каждый скаутский отчет, чтобы выяснить, какие из этих слов встречаются в документе. Например, есть популярная связка-тема «бросок», «свободный» и «линия» — очевидно, что в документах, где все эти три слова встречались вместе, говорилось об умении игрока наносить штрафной удар. По этой методике с помощью упомянутого алгоритма были выделены сотни таких тем.
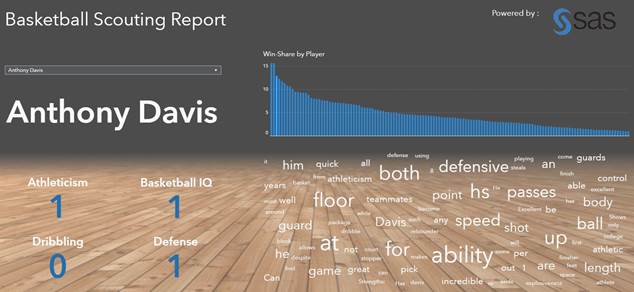
На отчете ниже отображены 4 из 17 категорий, выделенных на основе правил, в отношении игрока Энтони Дэвиса. В записях скаутов о нем говорилось, что он спортивен, обладает хорошим баскетбольным мышлением и силен в защите, однако ничего не было сказано об умении владеть мячом.
Прогнозирование будущих результатов
С помощью методов текстовой аналитики, описанных выше, мы проанализировали около 900 скаутских отчетов, датированных 2009–2015 годами, каждый из которых был посвящен одному игроку. Массив данных, полученный в результате этого анализа, использовался для построения прогнозных моделей и предсказания будущих результатов игрока.
В качестве целевой переменной для каждого игрока при прогнозировании его будущих результатов использовалось среднее значение трех самых высоких показателей рейтинга win-shares, который показывает влияние действий игрока на победу команды. В модель не включались игроки, отобранные после 2015 года, поскольку они, возможно, еще не отыграли свои лучшие сезоны.
Прогнозная модель показала многообещающие результаты. Предсказанные значения рейтинга win-shares в числовом выражении не совпадали с реальными, но ранжирование игроков по этому рейтингу было достаточно точным. В таблице ниже в левой колонке показаны десять лучших игроков, которые, согласно этому прогнозу на основе данных, полученных исключительно из неструктурированных отчетов скаутов, получат самый высокий рейтинг win-shares. В правой колонке — реальный топ-10 рейтинга win-shares.
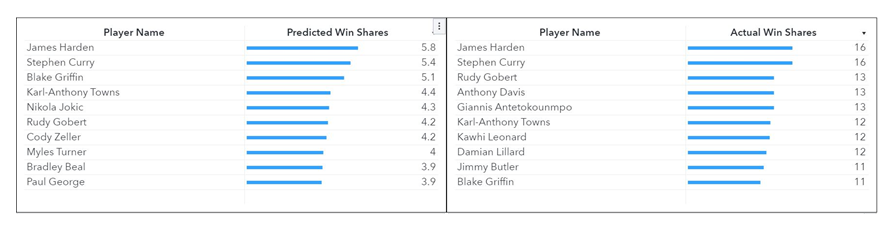
В прогнозе есть некоторые очевидные упущения — например, не указаны Энтони Дэвис и Яннис Адетокунбо, а некоторые другие игроки были оценены моделью слишком высоко. Однако не стоит забывать о человеческом факторе — никакая модель не способна исправить ошибки или преувеличения в отчетах. Если тренер или скаут напишут слишком лестный отчет о слабом игроке, то модель будет воспринимать это как данность и выдаст «звездный» прогноз для посредственности (и наоборот).
Нивелировать этот фактор и повысить точность анализа можно, но для этого требуется гораздо больше скаутских отчетов. Чем больше будет текстовых данных о каждом конкретном игроке, тем лучше будет работать модель. Кроме того, это расширяет поле зрения — у всех скаутов разные мнения, плюс к тому одни могут увидеть сильные или слабые стороны, которые не заметили другие.
Подобный анализ может принести пользу практически в любом виде спорта. Алгоритм не только экономит огромное количество времени, но и оценивает игроков без какой-либо предвзятости, которая может быть у человека. Например, возраст спортсмена, команда, в которой он играл раньше, страна, из которой он родом, могут подсознательно повлиять на выбор, сделанный человеком, но не на действия алгоритма.
Да, критики спортивной аналитики правы, когда они говорят, что данные не передают яркость спортивных моментов, как трансляции. Однако если задействовать источники неструктурированных данных, это значительно повышает уровень аналитики, результаты которой станут красноречивым ответом любым скептикам. Потому что приложения не ограничиваются только прогнозированием будущих выступлений новых профессиональных игроков. Анализ текста может помочь командам с выбором игрового дня для матча и работой с фанатами.






