Кейс: programmatic native для новой книги Дмитрия Глуховского
Вы когда-нибудь задумывались, что телефон стал резервным хранилищем для души? В нем вы храните самые яркие воспоминания – смех, мгновения счастья в фотографиях и видео. Вся ваша работа порой умещается в почте, браузеры хранят список ваших интересов, чаты – признания и чувства, свидетельства слез и обид. Телефон – это вы. И кто его получит, тот станет вами. А когда это откроется, то будет поздно

Об этом новая книга «ТЕКСТ» Дмитрия Глуховского, жанр
которой трудно описать – это триллер, роман-нуар, драма, история о
столкновении, бесполезном возмездии. В общем, первый реалистичный роман автора,
прославившегося в жанре постапокалиптики. Книга вышла в июне 2017 года в
издательстве «АСТ».
Дмитрий Глуховский – журналист, корреспондент,
объездивший полмира и проведший прямой эфир с Северного Полюса. Вел
передачи на радио, писал для СМИ. Широкую известность приобрел как автор
популярной трилогии «МЕТРО», каждая часть которой была
переведена на десятки языков. В 2007 году первая часть – «Метро 2033» –
получила награду «Лучший дебют» EuroCon. Сюжет «Метро» лег в основу
компьютерной игры «Метро 2033: Страх грядущего», получившей продолжение –
«Метро: Луч надежды».
Для нестандартной истории – нестандартное размещение. Продвижение в
programmatic-каналах в рамках промокампании книги для издательства «АСТ»
осуществляла платформа Auditorius. Для этого был выбран продукт
Programmatic Native, с помощью которого разместили рекламные
сообщения в видео- и
баннерном форматах. Несколько параллельных
стратегий позволили коммуницировать с различными аудиториями: во-первых, была
учтена степень знакомства пользователей с автором и его творчеством, а
во-вторых, опробованы гипотезы по реакции на видео и баннерный контент. Какая
стратегия показала себя лучше – скоро узнаете.
Почему был выбран именно нэйтив? Новоиспеченному роману как нельзя кстати
подходит контентное продвижение, а в этом нативной рекламе пока нет
равных.
Ход рекламной кампании
Итак, какие задачи и KPI были поставлены:
• Увеличить знание о продукте, т.е. о выходе новой книги (KPI – уникальный
охват);
• Косвенная поддержка продаж нового романа путем увеличения знания о продукте
(KPI – нажатие на кнопку «переход в магазин»);
Кампания проходила в течение 1,5 месяцев, а рекламные материалы
демонстрировались пользователям, проживающим в городах-миллионниках.
Как говорилось выше, в рамках рекламной кампании использовались два основных
формата – video native и display native. А теперь подробнее про каждый из
них.
VIDEO
Нативное видеоразмещение (out-stream видео, т.е видеореклама, размещаемая
вне видеоконтента, например, внутри статьи при пролистывании нескольких абзацев
текста) проводилось на базе аудиторных закупок как по сегментам стандартной
таксономии, так и по кастомным сегментам, среди которых:
– Геймеры. Это сегмент, включивший в себя пользователей, обладающих поведенческими маркерами геймеров, любителей компьютерных игр. Поведенческие маркеры: за последнюю неделю пользователь посещал не менее 5 страниц по темам «компьютерные игры», «симуляторы», «приставки», «консоли».
– Игровые приставки. Пользователи, которые интересуются игровыми консолями, приставками, аксессуарами.
– Активный отдых. Пользователи, которые интересуются
активным отдыхом, туризмом, велопрогулками, подвижными играми.
– Любители семейного отдыха. В сегмент попадут пользователи, которые
за последнюю неделю посещали не менее 5 разных страниц, посвященных путешествию
с ребенком, турам с детьми, детским отелям, направлениям отдыха с детьми,
детским экскурсиям, развлечениям для детей и т.п.
– Гик-культура. Пользователи, которые интересуются популярной культурой, фантастикой, компьютерными играми, комиксами, анимэ и прочими популярными увлечениями.
– Бизнес-новости. Пользователи, которые интересуются новостями в области бизнеса и экономики.
Было использовано три видеоролика. Два из них демонстрировались на
протяжении всего периода размещения. Это ролики, знакомящие читателя с сюжетом
«Текста». Видеоряд был создан командой писателя, которая давно с ним работает,
и отражал общее настроение книги. Третий ролик был добавлен к креативам на
последней неделе размещения. Его показывали на женскую аудиторию. Он получился
самым неожиданным и менее «рекламным» из всех креативов.
DISPLAY
Нативное размещение тексто-графических объявлений проходило на базе
контекстуального таргетинга только на сайтах с лицензионным контентом (более
300 площадок с охватом в 25 млн
пользователей, среди которых echo.msk.ru, europaplustv.com,
igromania.ru, sport-express.ru и другие).
Контекстуальный таргетинг – это доставка целевой рекламы потребителям в
зависимости от просматриваемого ими контента. Характеристики пользователей
можно определять на основе содержания URL, которые они посетили. Например, при
посещении пользователем страницы со статьёй, посвящённой советам молодым мамам,
можно показывать баннер с рекламой детского питания или памперсов. Либо
пользователям, интересующимся автомобильной тематикой, предлагать рекламу
автомобильных дилеров или магазинов автозапчастей, в зависимости от контента
URL. Для отнесения URL к той или иной категории необходим классификатор текста
на основе методов искусственного интеллекта и машинного обучения.
Классификатор представляет собой алгоритм или комитет алгоритмов, таких как
«наивный байесовский алгоритм» (“naïve bayes”) либо «случайный лес» (“random
forest”), рассчитывающий некоторое расстояние или вероятность принадлежности
контента к одному из заранее определённых классов. Таким образом, классификация
относится к классу задач «с учителем», для чего требуется предварительно
пометить примеры контента известным классом или классами (в последнем случае
классификация называется множественной, к примеру, контент может одновременно
принадлежать к категориям «ауди», «легковые машины», «ремонт
автомобилей»).
В случае обычной классификации примеры и целевой объект сразу представлены
векторами, содержащими числовые значения. Если же мы имеем дело с текстами,
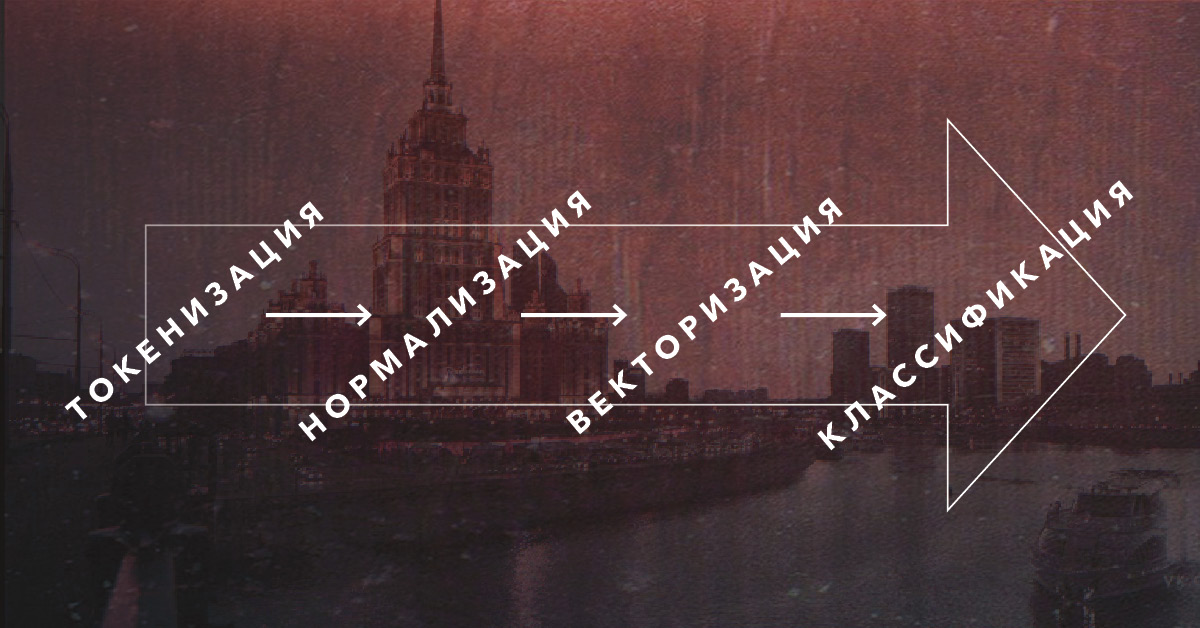
требуется предварительная подготовка таких данных. Вначале производится
операция токенизации, т.е. разделения исходного текста на токены – минимальные
смысловые единицы. Для разных случаев токенами могут выступать как отдельные
слова или наборы из n-слов (n-граммы), так и предложения или строки из
определенного количества символов. После получения токенов, если они являются
словами, для сокращения лишней информации производится их лемматизация или
стемминг – приведение к некоторой начальной форме, либо основываясь на
словарных формах, либо путём отбрасывания окончаний. Например, слово
«подозревающий» превращается в «подозревать». А если нам попадается слово
«экшн-камера», то разбивая его на два слова, мы теряем исходный смысл выражения
и можем получить предполагаемый интерес пользователя в виде кино, вместо
активного отдыха. Здесь как раз и понадобятся n-граммы.
Слова в примерах и целевых URL обычно повторяются, некоторые реже, другие чаще.
Часть из этих слов связаны со стилем написания, часть является предлогами или
узкоспециализированными терминами или жаргоном, связанным с тематикой контента.
Для отбрасывания лишнего используется фильтрация по словарным спискам, а также
частотный анализ, например, с использованием меры TF-IDF, которая позволяет
подсчитать относительную значимость слова по всему набору (называемому в
текстовом анализе корпусом) имеющихся документов. Результатом такого
преобразования являются числовые вектора, которые можно сравнивать между собой
стандартными математическими и статистическими метриками.
Для повышения точности классификатора требуются наличие большого количества примеров и проработанная таксономия тематик изучаемого контента. Таксономия обычно представляет собой граф понятий или тематик (чаще всего в виде древа - иерархии), к которому предъявляется ряд требований, в большей степени это полнота, непротиворечивость и неизбыточность. С точки зрения полноты, тематики должны системно и всесторонне описывать предметную область, в крайнем случае допускается вариант «другое», если полный перечень тематик невозможно/нецелесообразно составить. Непротиворечивость и неизбыточность означают согласованность тематик при движении по этой иерархии в любом направлении. Однако это не всегда возможно, и в этом случае граф тематик должен содержать циклы. Например, тематика «мерседес» может быть отнесена как к тематике «легковой транспорт», так и к тематике «коммерческий транспорт», а также к тематикам «бизнес» и «автомобильный бизнес».

Наличие сложных, неоднозначных связей между тематиками приводит к построению комплексных алгоритмов классификации, для реализации и перенастройки которых требуются значительные интеллектуальные и вычислительные ресурсы.
Кроме того, для работы в реальных условиях контекстный таргентинг должен производиться практически мгновенно, чего можно добиться за счёт использования информационной архитектуры, рассчитанной на параллельную обработку BigData, такой как, например, связка Hadoop+Spark.
Таким образом мы брали статьи, посвященные заклеиванию web-камер, отказу от
телефонов, digital-detox, сериалу «Черное зеркало» и пр. То есть немного
гик-тематики, помноженной на свойственную интернет-пользователю легкую
паранойю. При раскладывании мы получали следующее:
Пример статьи

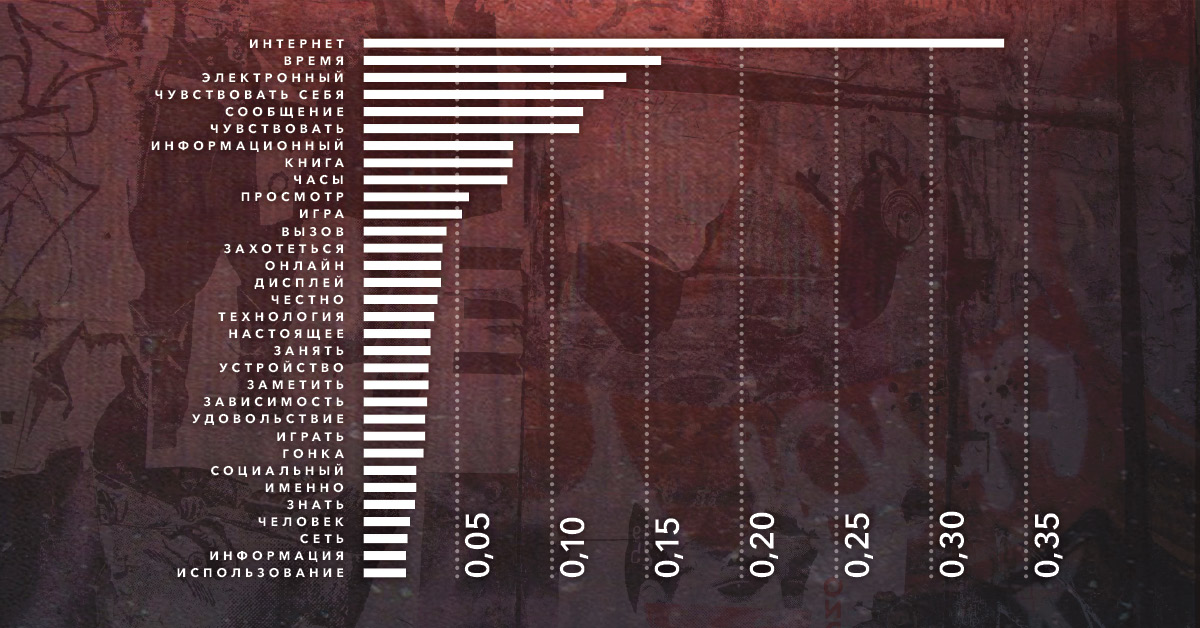
Пропускаем текст статьи через программу классификации веб-страниц и видим, что основная категория слов (т.е. категория с наибольшим весом, присвоенным после анализа статьи) относится к тематике «Люди и общество» (40% всего содержания).
Кроме того, слова и сочетания рассматриваемой страницы, удовлетворяющие пороговым значениям выбранной частотной меры, можно использовать в качестве инсайтов для формирования рекламного сообщения, посадочных страниц и определения вектора рекламной коммуникации:
В рамках кампании были использованы все основные нативные форматы размещения: in-feed (в новостной ленте сайта), рекомендательный виджет (рекомендация к прочтению, «вам может понравиться»), in-content (в тексте самой статьи), banner style (выглядит как стандартный баннер, но может подстраиваться под окружение, т.е. мы получаем «резиновую» картинку, подставляемую на любое место в любом формате).
Сообщения не содержали прямого рекламного призыва, на самих баннерах не было изображения книги, а, следовательно, были соблюдены главные правила нативного размещения. Однако изображения как вызывали интерес пользователей, так одновременно и шокировали их, что впоследствии сказалось на метрических показателях стратегии.
Пример рекомендательного виджета
Какие результаты принесла реализация на первый взгляд простого сценария с использованием достаточно молодого инструмента programmatic native?
Для начала проанализируем изменение метрических показателей, ведь, как известно, нэйтив – это про качество трафика.
На рисунке представлены 3 графика, демонстрирующих всю суть работы автоматической оптимизации programmatic-кампании: первая неделя – старт кампании – алгоритм предиктивной оптимизации только набирает «входную» информации для обучения. Вторая неделя – «разгон» рекламной кампании, активная работа контекстуального таргетинга в совокупности с автоматической оптимизацией и ручным изменением настроек (отключение неэффективных сегментов, перераспределение инвентаря и прочее) уже дают свои результаты: ко второй неделе показатель отказов снизился на 37%, а глубина просмотров увеличилась почти в 1,5 раза. Третья и четвертая недели – выход на плановые показатели, стабилизация положительной динамики. Пятая и шестая неделя – максимальный эффект, сохранение достигнутых результатов.
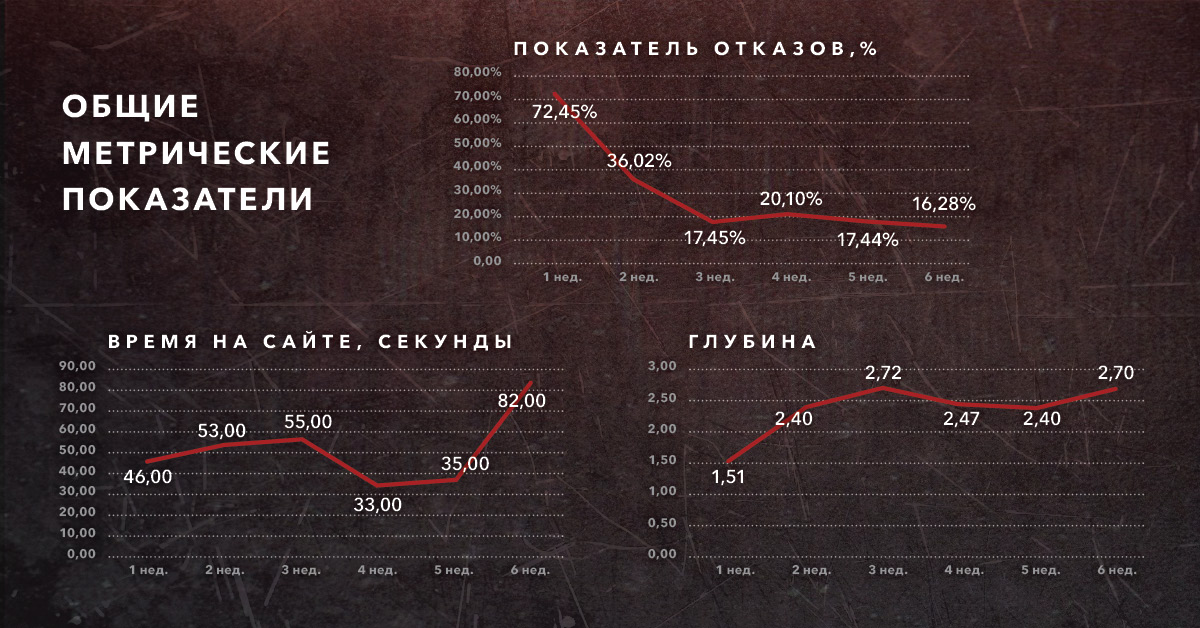
В итоге мы видим, что за весь период кампании количество отказов (BR) снизилось с 73% до 16%; время, проведенное пользователями на сайте, выросло с 00:46 до 1:22 минут, а глубина просмотра увеличилась с 1,5 до 2,7 страниц. Сравнение проводилось по метрическим показателям сайта в начале кампании и после размещения. Это лучшие показатели среди всех подключенных источников трафика за заданный период.
Как и с любым другим programmatic-размещением, во время флайта мы постоянно следили за результатами, которые демонстрировали подобранные аудитории, и при необходимости корректировали стратегию. Безусловно, лучше всего показала себя аудитория людей, уже знакомых с творчеством Дмитрия Глуховского. Пользователей из этой категории можно отнести к поклонникам творчества писателя, которые ожидали выхода новинки. Половина не досматривала ролик до конца, а сразу переходила на сайт. CTR этих роликов достиг 2,78%.
Незнакомые с творчеством люди лучше реагировали на сам видеокреатив.
Показатель досмотра ролика в этой категории составил почти
61%, а CTR – 1,68%.
CTR по баннерному нативному размещению не такой высокий –
0,2%. Это связано с моделью CPM, которая в дисплейных
размещениях дает CTR ниже, чем модель CPC. Однако, показатели постклика по
нейтиву значительно лучше других опций.
Применение нативного формата и вовлечение пользователя в продукт через ненавязчивые яркие визуальные рекламные форматы позволили охватить 2 145 935 уникальных пользователей. Общее количество конверсий «переход в магазин» составило 3 229.
Помимо этого, за весь период рекламной кампании 9 054 человека прочитали первую главу, размещенную на сайте проекта.
Кроме анализа метрических показателей мы сделали срез аудитории, посещавшей сайт проекта, и вывели новые сегменты, которые можно использовать для следующих рекламных флайтов. Для этого мы выбрали сегменты с минимальным пересечением (т.е. пересечение с теми пользователями, которые уже задействованы в наших других сегментах) и максимальным индексом аффинитивности.

Таким образом, наиболее подходящими оказались следующие сегменты:
- Досуг и развлечение: музыка
- Спорт
- Досуг и развлечение: кино
- Игры
- Путешествия
ВЫВОД
Продвижение литературы в интернете – нетривиальная задача. С одной стороны, нужно четко попасть в аудиторию т.н. «креативного класса», с другой – преодолеть сильный «информационный шум», в котором она живет. Для того, чтобы зацепить внимание этой аудитории интернет-серферов, мы использовали наиболее сильный с точки зрения задействованных каналов воздействия формат – видео. Фактически, продвигая литературу, мы использовали особенности восприятия современной аудитории, т.н. «клиповое сознание». Переведя литературный язык на язык визуальных образов видеорекламы, мы вызвали моментальный интерес, который конвертировали в знакомство с первой главой на сайте издательства. Одновременно с этим, мы применили продвинутые алгоритмы машинного обучения для нахождения в интернете конкретных веб-страниц, тематика которых в наибольшей степени пересекается с тематикой книги. Дальнейшее автоматизированное размещение рекламы книги на этих страницах показало отличный результат: посетители демонстрировали высокий интерес к информации о выходе книги, проявившийся в метрических показателях на сайте издательства. На практике мы увидели, что стандартный аудиторный таргетинг, который углублен контекстуальным анализатором, дает возможность найти любую, даже самую специфическую аудиторию, которая продемонстрирует отличные показатели вовлеченности. Но, сразу хотим предупредить, что такой микс programmatic-инструментов не является «золотой пулей» для решения любых задач. Его «конек» – engagement. Для достижения performance-показателей необходимо использовать более сложный комплекс инструментов, с применением триггерных сценариев и интерактивных механик внутри видео. Об этом – в наших следующих кейсах.



