Кейс «Энергия» и PREMIER: как помочь онлайн-кинотеатру услышать своих зрителей
О том, как искали нестандартный подход к задаче с помощью искусственного интеллекта и какие результаты он принес, — в кейсе

Цель
Провести масштабное SL-исследование рынка онлайн-киносмотрения и тайтлов.
Клиент
PREMIER — онлайн-кинотеатр.
Проблематика
Когда приступили к работе, то столкнулись с беспрецедентным объемом пользовательского контента о сериалах и платформах за 2023 год. Стандартные методы анализа здесь не подходили, но мы не хотели идти на компромисс со снижением качества или отказываться от проекта.
Решение пришло через эксперименты: команда применила искусственный интеллект для обработки данных, что позволило за три месяца провести полноценное SL-исследование рынка.
Реализация
Миссия: обработать миллионы мнений
Онлайн-кинотеатр PREMIER стремится понять своего зрителя. Что его привлекает? Почему он выбирает тот или иной сериал? Какие факторы останавливают его от подписки? Ответы на эти вопросы позволяют не только создавать контент, который цепляет, но и повышать лояльность аудитории, улучшать пользовательский опыт и стимулировать продажи.
В PREMIER собралась команда, которая смотрела на развитие продукта стратегически и ориентировалась на построение своей аналитики не только на внутренней статистике, но и на основе пользовательского шлейфа — тех самых высказываний, которые миллионы людей оставляют в соцсетях, на форумах и в комментариях.
Однако данные — это не всегда ясная картина. Это скорее хаос, который нужно структурировать. За год у PREMIER накопилось 10 млн упоминаний в интернете.
Онлайн-кинотеатр поставил задачу обработать сверхмассивные и сверхразнородные данные:
-
Превратить разрозненные мнения в структурированные данные, готовые для анализа.
-
Очистить массив от информационного шума и оставить только релевантные тексты.
-
Разметить упоминания по 175 тегам, чтобы можно было видеть, о чем говорят пользователи (жанры, платформы, упоминания актеров, жалобы и так далее).
-
Выявить паттерны, которые помогут понять драйверы и барьеры на пути зрителя к подписке.
-
В процессе работы добавилась еще одна амбициозная задача, которую мы поставили себе сами, — разработать инструмент, позволяющий команде PREMIER работать с результатами исследования быстро и удобно.
На первый взгляд, это был классический проект Social Listening — исследования на основе анализа UGC, или пользовательского контента. Однако масштаб задачи выводил его за рамки стандартных подходов.
Ручная обработка здесь не помогла бы — даже если бы за проект взялись 100 асессоров, они не смогли бы справиться с таким объемом за отведенное время. Более того, такой подход потребовал бы огромных ресурсов и обошелся бы очень дорого. Нам выделили всего три месяца, поэтому поиск эффективного автоматизированного решения стал единственным выходом. Вместо попыток сделать все вручную мы сделали ставку на искусственный интеллект.
Антон, Product Director:
«Асессор — специалист, который проверяет каждое упоминание: размечает соответствующими тегами и определяет его тональность, удаляет мусор».
Сбор данных
Сначала нужно было собрать все упоминания. Для этого использовали систему Brand Analytics, которая отслеживает публикации в интернете по заданным ключевым словам. Инструмент мониторит тысячи источников, включая соцсети, форумы, блоги, новостные сайты. На этом этапе появилась проблема: часть источников не подтягивалась автоматически, поэтому пришлось дополнительно разработать парсеры.
Парсер — это специальная программа, которая собирает данные с сайтов по определенным правилам. Парсить можно любую доступную в публичном поле информацию, а также упоминания, мнения, отзывы и рецензии на сериалы и онлайн-кинотеатры, что мы и сделали. Для качественного сбора искомых данных мы создали десятки парсеров.
В результате собрали тексты из 5 400 источников. В этот массив вошло все: от восторженных отзывов до технических жалоб.
От хаоса к системе: разрабатываем пайплайн
Чтобы обработать собранные упоминания, нужна методология, которая превратит разнородный поток данных в ясные и полезные инсайты. Так началась разработка пайплайна — многоэтапного процесса обработки информации.
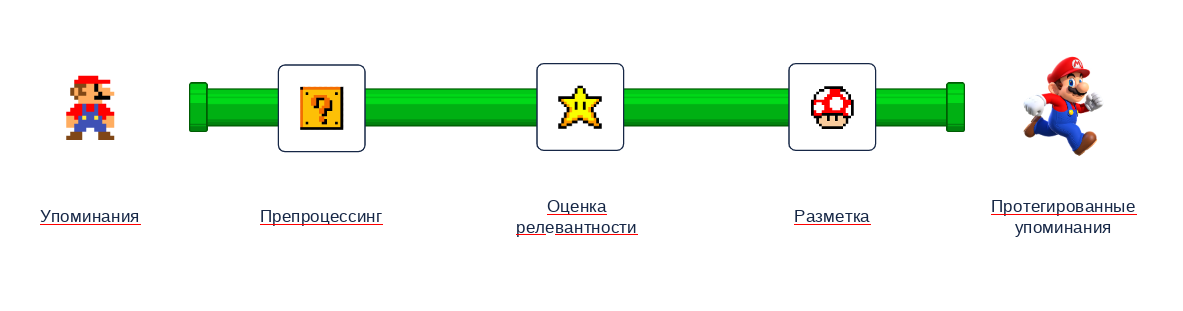
Пайплайн похож на конвейер: каждый этап подготавливает данные для следующего, пока на выходе не получается готовый продукт.
Разработанный пайплайн включал в себя несколько ключевых этапов:
1. Очистка данных от информационного мусора
Когда упоминания были собраны, оказалось, что часть информации не подходит для анализа. Нужно было избавиться от всего лишнего. Процесс очистки данных включал в себя:
-
Удаление дублирующихся текстов.
-
Исключение сообщений, не относящихся к теме (например, рекламы или ссылок).
-
Удаление эмодзи, иероглифов, случайных символов.
-
Отсев слишком коротких и слишком длинных текстов, перегруженных бесполезной информацией.
2. Определение релевантности
После очистки оставшиеся данные нужно было проверить на релевантность. Это значит убедиться, что текст относится к задаче клиента. Важно понять, какие из упоминаний полезны для анализа. Команда определила релевантный контент как выражения мнений людей о сериалах и платформах.
На этом этапе применили модели машинного обучения (Machine Learning), так как посчитали, что они будут работать лучше всего. Это алгоритмы, которые учатся на примерах, чтобы различать, что подходит для задачи, а что нет. Например, сначала модели показывают тексты и говорят: «Вот это — полезное упоминание, а это — нет». Затем алгоритм начинает применять полученные знания к новым данным.
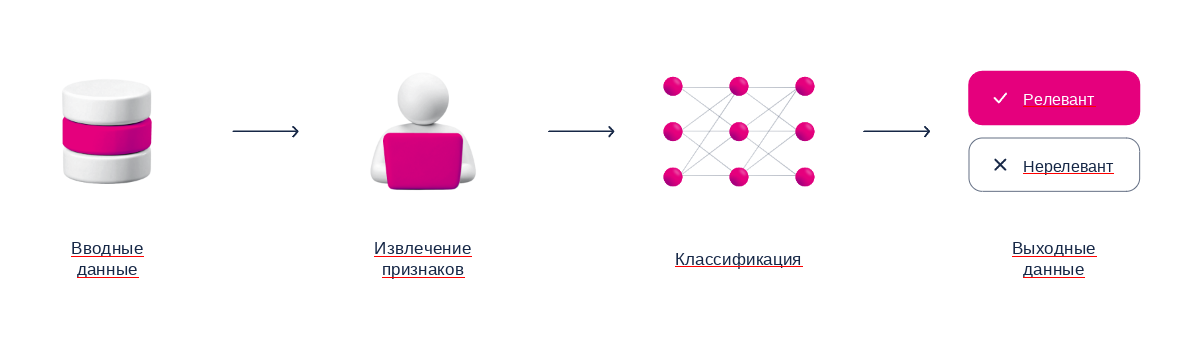
Процесс автоматизирован, но не всегда универсален. Для нашего проекта метод оказался недостаточно эффективным. Тогда команда перешла к использованию моделей глубокого обучения (Deep Learning), которое работает более сложным образом — через множество слоев анализа.
Преимущество в том, что такую модель можно дополнительно обучать под конкретные задачи. После ее применения точность фильтрации достигла 95% — модель почти безошибочно определяла подходящие данные.

Кластеры отзывов и не-отзывов, получившиеся в результате финального подхода
3. Тегирование
Теперь, когда остались только полезные упоминания, нужно было понять, о чем именно они говорят. Для этого применили разметку по тегам.
Каждое релевантное упоминание проходило через систему анализа, где его отмечали тегами (жанр, платформа, упоминание актера и так далее). Каждый текст мог иметь несколько тегов. Например, комментарий «Ужасный сценарий, но актеры вытянули!» одновременно относится к категориям «актеры» и «сюжет». Всего — 175 разных тегов. Это помогло бы PREMIER быстро находить ответы на различные вопросы:
- Какие жанры любят пользователи?
- Какие проблемы вызывают наибольшее количество жалоб?
- Какой контент провоцирует активное обсуждение?
Для разметки использовали три подхода:
- Эвристика — набор четких правил для простых случаев. Например, если в тексте есть слово «комедия», то тег будет #жанр_комедия.
- Open Sourse DL — модели считывали в текстах смыслы и скрытые связи.
- GPT-3.5 — мощная модель для самых сложных задач, она помогала распознавать редкие паттерны.
По внутренним метрикам, в финальной версии пайплайна нам удалось добиться крайне высокого качества работы. Точность составила 85%. Это высокий показатель для такого объема данных. К примеру, группа асессоров в среднем размечает данные с точностью около 88%.
Качественно подготовленный пайплайн практически не уступает ручной разметке, но, кроме того, оптимизирует и автоматизирует процесс, сокращая затраты на временные и человеческие ресурсы.
Искусственный интеллект в действии
Ключевой этап работы заключался в обучении моделей. Для этого команда асессоров вручную разметила около 7% данных (более 25 000 строк текста), чтобы алгоритмы могли учиться на примерах.
Для редких случаев использовали аугментацию — процесс, при котором создаются искусственные примеры данных. Например, на основе одного отзыва можно сгенерировать несколько вариантов, сохранив его смысл. Метод позволил классифицировать редкие теги, которые встречались всего несколько раз в огромном массиве данных.
Аугментация — это увеличение числа примеров упоминаний для редких тегов за счет генерации неорганических упоминаний с помощью нейросетей. В дальнейшем эти датасеты будут использованы для дообучения DL-модели, чтобы та смогла с большей точностью определять редкие теги.
Антон, Product Director:
«Хорошо настроенный пайплайн с фиксированной картой тегов будет справляться с разметкой лучше, чем целая команда асессоров».
Результаты
Что нового появилось у команды PREMIER
Библиотека кластеризированных массивов
10 млн упоминаний были очищены, размечены и разделены на категории. Теперь эти данные можно использовать повторно для любых исследований.
Масштабное SL-исследование рынка и аналитические инсайты
Данные превратились в отчеты, которые помогли команде PREMIER глубже понять свою аудиторию и работать над маркетинговой стратегией. Дополнительно собрали ключевые чек-листы для принятия регулярных решений по креативным и продуктовым задачам.
Воркшоп
Чтобы поставить красивую точку в этом проекте, провели большой тематический воркшоп по результатам анализа для креативных команд. На встрече обсудили разноформатные идеи по улучшению продукта и пользовательской коммуникации на основе тех инсайтов, которые получили во время исследования.
Чат-бот AI-Premier
Это полноценный аналитический инструмент, который ориентируется в ранее подготовленных данных и выполняет функции аналитика. Он умеет не только отвечать на вопросы в реальном времени, но и анализировать тренды, считать упоминания, сравнивать показатели, сводить статистику по тегам и выявлять схожие паттерны.
Например, если спросить его, какие сериалы больше всего обсуждались в сентябре, он не только выдаст список, но и покажет динамику упоминаний, сравнит с предыдущими месяцами и выделит ключевые темы обсуждений.
Анна, Account Director:
«Мы уже не могли остановиться и решили сделать еще одну ассистирующую фичу. Поскольку не все члены команды PREMIER имеют время и ресурс пойти на раскопки внутрь массивов, мы придумали ассистента, который вместо них мог бы найти данные и выдать в сжатой форме».
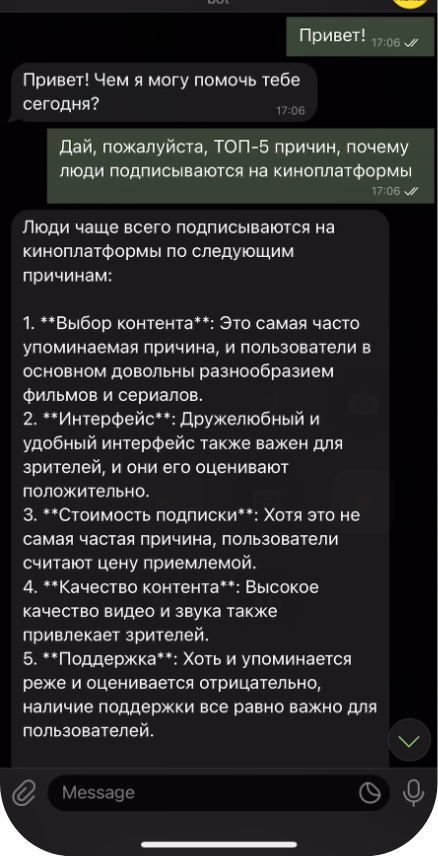
Аналитический AI-бот отвечает на тематические вопросы на базе 10+ млн размеченных упоминаний
Чем уникален кейс
Этот проект стал примером того, как AI может не просто помогать, но и менять подход к аналитике.
- Масштаб задачи: обработка 10 млн упоминаний за три месяца.
- Технологический подход: сочетание машинного обучения, глубокого обучения, эвристики и GPT-3.5.
- Практическая ценность: клиент получил не только исследование, но и инструмент для работы с данными на постоянной основе — AI-ассистента, который моментально отвечает на любой вопрос, используя полученные результаты. Датасет при необходимости можно обновлять и расширять за счет внесения новых данных.
Вот такой получился кейс: коллаборация с PREMIER и готовность экспериментировать привела нас к созданию нескольких новых продуктов, готовых к масштабированию в других областях. Особенно впечатляет, как синергия наших команд трансформировалась в решения, которых раньше не было на рынке.
Реклама. Рекламодатель ООО «Джами» ИНН 7725688242



