«Умный» ремаркетинг, или как удвоить конверсии с кампаний ремаркетинга с помощью машинного обучения
Кирилл Костыренко, веб-аналитик Риалвеб, о плюсах «умного» ремаркетинга

Обычно аудитории ремаркетинга настраивают «на глаз», никто не знает, какой у них потенциал и как выжать из ремаркетинга максимум. Главная проблема в том, что информация о посещениях пользователей содержит сотни комбинаций параметров и невозможно настроиться на всевозможные аудитории.
Глазами можно отследить только основную закономерность в данных, а что делать с остальной информацией? В итоге мы возвращаем не всех наших потенциальных клиентов и тратим рекламный бюджет на пользователей, которые в нашем продукте мало заинтересованы или не заинтересованы вовсе.
В качестве примера приведу показатели кампаний ремаркетинга одного рекламодателя из сферы недвижимости в Google AdWords за август 2019. Результаты говорят сами за себя — показатель отказов очень высок:

Выход очевиден — мы должны проанализировать все признаки наших текущих клиентов и выявить показатели, которые однозначно смогут отличить их от пользователей, не ставших нашими клиентами. Если мы хотим выявить закономерности в больших массивах данных, то машинное обучение подходит как нельзя кстати для этой задачи.
Этап 1. Подготовка данных
Для начала необходимо обучить алгоритм на исторических данных с целью оценки вероятности совершения конверсии пользователем. Мы взяли данные по сессиям за прошедший год по клиенту из сферы недвижимости. Всего получилось около 800 тыс. сессий. Также нужно выбрать событие, которое определяет совершение конверсии пользователем.
Этап 2. Машинное обучение
В этой части я расскажу подробно о том, как строится процесс машинного обучения для «умного» ремаркетинга. Эта информация будет полезна техническим специалистам, которым знакомы принципы работы машинного обучения. Если же вы маркетолог и вам больше интересна практическая ценность данного подхода, то переходите к прочтению Этапа 3, где раскрывается внедрение алгоритма и его ценность.
Итак, рассмотрим простой алгоритм поиска паттерна признаков потенциального клиента:
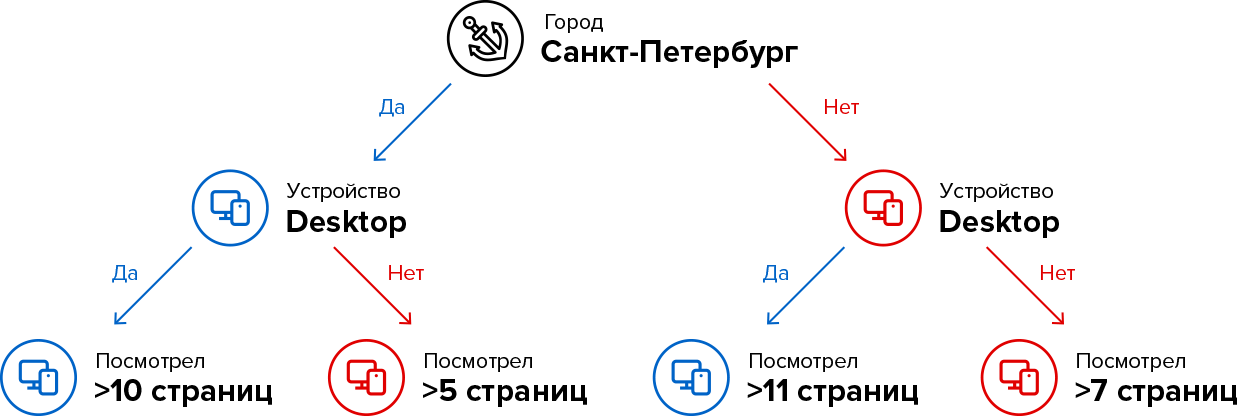
Такой алгоритм называется деревом принятия решений.
Очевидно, что одного дерева недостаточно, чтобы описать всевозможные паттерны признаков наших клиентов, для этого используются композиции деревьев, или «лес». Композиции деревьев отлично справляются с задачей классификации табличных данных. Для нашего проекта мы использовали самую эффективную реализацию описанного выше метода — градиентный бустинг решающих деревьев. Основная идея этого метода в том, что каждое следующее дерево строится таким образом, чтобы исправить ошибки уже построенной композиции.
С методом мы определились, теперь необходимо понять, как будем измерять точность работы алгоритма.
Обычно из тысячи посетителей сайта клиентами становятся только десятки или даже единицы. И если мы разобьем наших посетителей на два класса — «не стал клиентом» и «стал клиентом», то наши классы будут несбалансированными. В первом будет 99% посетителей, во втором —1%.
Если алгоритм определит всех наших посетителей как первый класс («не стал клиентом»), то получим точность 99%, но никакой пользы от такого алгоритма не будет. Поэтому мы оценивали не точность по всей выборке, а только качество оценок принадлежности к классу 1. Для этого используется матрица ошибок:
|
|
y=1 |
y=-1 |
|
a = 1 |
True Positive (TP) |
False Positive (FP) |
|
a= −1 |
False Negative (FN) |
True Negative (TN) |
Положительный класс (стал клиентом) обозначается единицей (1), отрицательный класс (не стал клиентом) — минус единицей (-1), множество всех предполагаемых ответов — (a), множество всех истинных ответов — (y). Если истинный положительный класс совпадает с истинным предполагаемым, то имеет место верное срабатывание (true positive), если не совпадает, то — ложное срабатывание (false positive). С отрицательными классами — аналогично.
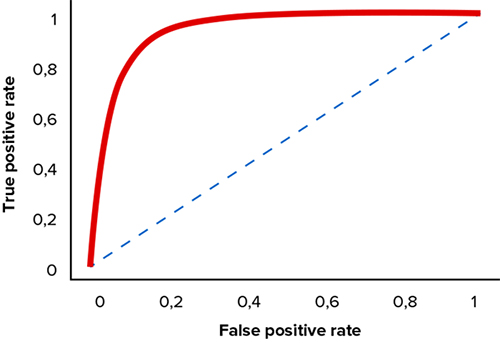
Один из способов измерить качество оценок принадлежности к классу 1 — ROC-кривая. Она строится на осях False Positive Rate (ось X), True Positive Rate (ось Y):

Осталось только понять, как оценивать принадлежность к классу.
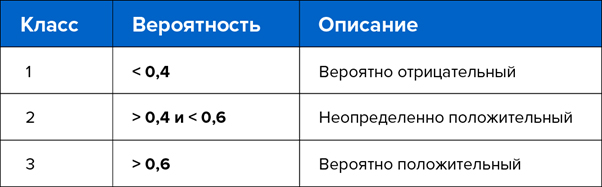
Дело в том, что алгоритм не может однозначно определить принадлежность к классу 1 или -1, вместо этого алгоритм оценивает вероятность принадлежности к классу 1. Вероятность принимает значения от 0 до 1, и если мы установим порог значений 0,5, то все объекты, имеющие вероятность ниже этого порога, будут отнесены к классу 0, а все объекты выше порога — к классу 1.
Таким образом, в зависимости от задачи или входных данных мы можем самостоятельно устанавливать порог значений.
ROC-кривая показывает зависимость FPR и TPR при варьировании порога от максимального значения к минимальному. Она проходит из точки (0,0), когда все вероятности находятся ниже порога, в точку (1,1), когда все вероятности лежат выше порога. Чем выше диагонали прямоугольника лежит ROC-кривая, тем лучше качество классификации.
Площадь под ROC-кривой (AUC — Area Under Curve) — это агрегированная характеристика качества классификации. Чем ближе площадь к единице, тем лучше модель классификации. В нашем случае площадь равна 0,94.
Делить вероятности по какому-то порогу — не очень хорошая идея, поэтому мы решили делить по двум порогам и получили три класса:
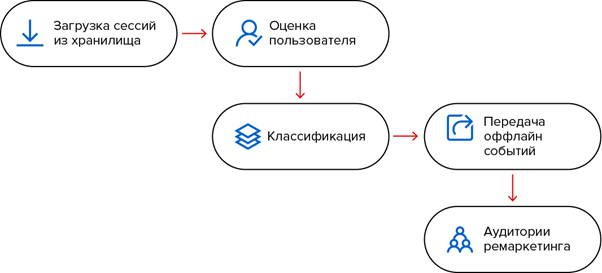
Архитектура приложения достаточно проста:
1. Загрузить сессии пользователей из системы сбора статистики. Здесь используются стандартные методы API Google Analytics и Yandex Logs API.
2. Оценить вероятность совершения конверсии.
3. По вероятности совершения конверсии разбить пользователей на классы.
4. Для пользователей с высокой вероятностью конверсии передать офлайн-событие в систему аналитики. Для передачи офлайн-событий используются Google Analytics Measurement Protocol и Yandex API offline-conversions.
Отдельно хочется отметить, что все списки пользователей, которые у нас попадают в систему и передаются в офлайн-события, — динамические. Динамика была достигнута за счет того, что алгоритм работает на сервере и автоматически обновляет списки 1 раз в сутки. Если класс пользователя увеличился, то отправляется офлайн-событие на повышение класса. В зависимости от сферы деятельности, где мы запускаем ремаркетинг, условие обновления списков может меняться.
Этап 4. Тестирование
Алгоритм тестировался в течение месяца совместно с традиционными кампаниями ремаркетинга в Google AdWords. Так как мы выявляли только тех пользователей, у которых вероятность совершения конверсии максимально высокая, то мы использовали повышенные ставки в контекстных рекламных кампаниях для этой аудитории. Тем самым мы гарантированно возвращали потенциальных клиентов, которые заинтересованы в предложении компании.
Результаты по традиционному ремаркетингу за сентябрь мало чем отличается от результатов за август, а вот «умный» ремаркетинг показал отличные результаты:
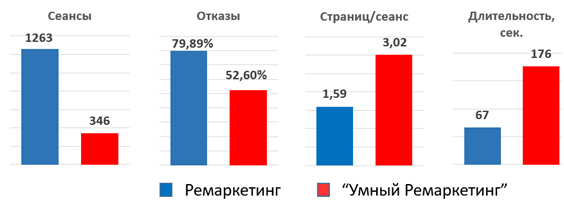
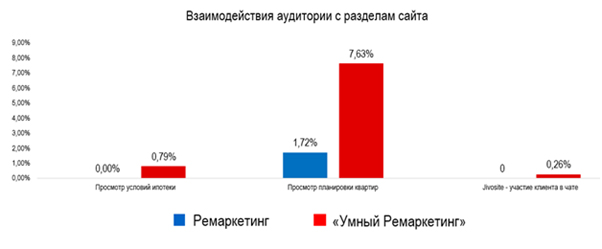
Но нашей основной целью было не увеличение показателей вовлеченности, а повышение конечной конверсии. В результате запуска выросло число прямых конверсий — в 2 раза, а также число ассоциированных конверсий — в 4 раза (лиды с сайта + звонки в CallTouch):
Выводы
По итогам тестирования можно сделать вывод, что «умный» ремаркетинг является отличным дополнением к традиционному ремаркетингу и позволяет гарантированно вернуть на сайт лояльных пользователей и в Google AdWords и в «Яндекс.Директ».
Основные плюсы «умного» ремаркетинга:
1. С высокой долей вероятности определяем ту аудиторию, которая действительно заинтересована в вашем продукте.
2. Выстраиваем стратегию ремаркетинга в зависимости от той задачи, которая перед нами стоит.
3. Предсказываем вероятность конверсии.
4. Использование повышающих ставок только для пользователей с высокой вероятностью конверсии
Алгоритм «умного ремаркетинга» является гибким инструментом, поэтому его можно применять во всех сферах онлайн-продвижения, изменяя лишь подбор параметров для обучения модели машинного обучения и частоту обновления аудиторных списков.
